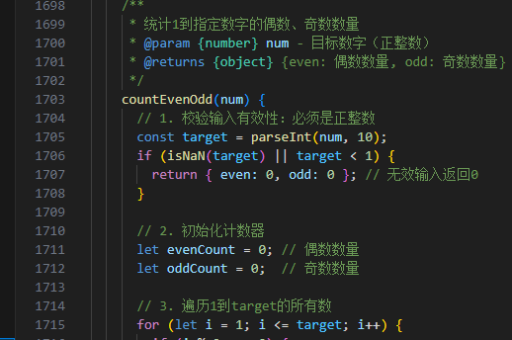
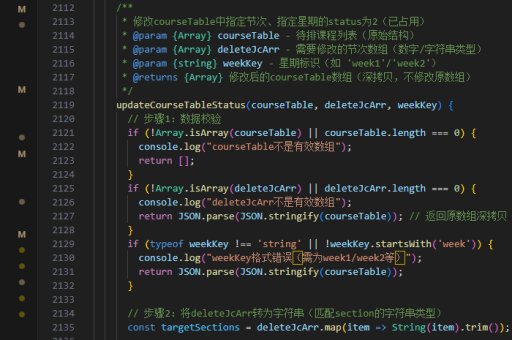
java大数据如何处理
Java大数据处理的核心技术
Java在大数据领域的应用广泛,主要依赖以下技术和框架:
Hadoop生态系统
Hadoop是分布式存储和计算的基础框架,Java是其原生开发语言。MapReduce编程模型用于批处理,HDFS提供分布式存储。Java开发者可通过API直接编写MapReduce任务,处理TB/PB级数据。
Spark框架
Spark的Java API支持内存计算,比Hadoop MapReduce快10-100倍。通过RDD(弹性分布式数据集)和DataFrame API,能高效处理流数据、机器学习等场景。Java 8的lambda表达式与Spark结合能简化代码。
Flink流处理
Flink提供Java API支持实时流处理,精确的状态管理和事件时间语义使其适合金融风控、IoT等场景。Window操作和CEP(复杂事件处理)功能可通过Java实现。
数据处理优化方法
内存管理技巧

- 使用堆外内存(DirectBuffer)减少GC压力
- 配置JVM参数(-Xmx, -XX:+UseG1GC)
- 对象复用(避免频繁创建对象)
并行化策略
- 合理设置Spark的partition数量
- 使用ForkJoinPool处理CPU密集型任务
- 避免共享可变状态,采用不可变集合
常用工具链整合
数据序列化
- Avro/Protobuf的Java绑定
- Kryo序列化(Spark中配置)
连接器生态

- Kafka Java Client消费实时数据
- JDBC连接传统数据库(如MySQL)
- Elasticsearch的Java High Level REST Client
性能监控与调试
JVM工具链
- VisualVM监控堆内存
- Async Profiler分析CPU热点
- GC日志分析(-XX:+PrintGCDetails)
分布式追踪
- OpenTelemetry Java SDK
- Spark UI/Flink Web UI观察作业DAG
示例代码片段(Spark Java API):
Dataset<Row> df = spark.read().json("hdfs://path/to/data");
df.groupBy("department")
.agg(avg("salary"), max("age"))
.write()
.parquet("hdfs://output/");关键点在于根据数据规模选择合适框架,结合Java生态工具链,并通过性能调优确保处理效率。对于超大规模数据,需考虑Kubernetes等容器化部署方案。