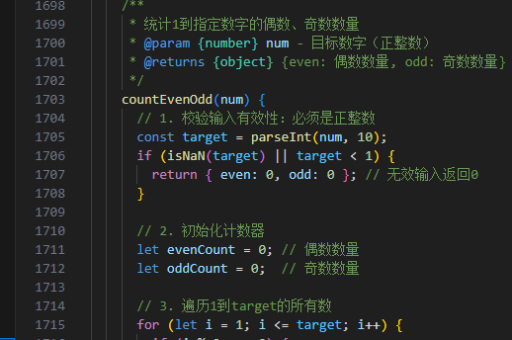
java如何控制分组
控制分组的方法
在Java中,控制分组通常涉及集合操作、流处理或正则表达式等场景。以下是几种常见的分组控制方法:
使用Stream API进行分组
Java 8引入的Stream API提供了Collectors.groupingBy方法,可以方便地对集合元素进行分组:
List<String> items = Arrays.asList("apple", "banana", "apple", "orange");
Map<String, List<String>> grouped = items.stream()
.collect(Collectors.groupingBy(Function.identity()));正则表达式分组
正则表达式中使用括号()可以创建捕获组,通过Matcher对象获取分组内容:
Pattern pattern = Pattern.compile("(\\d+)-(\\d+)");
Matcher matcher = pattern.matcher("123-456");
if (matcher.find()) {
String group1 = matcher.group(1); // "123"
String group2 = matcher.group(2); // "456"
}自定义分组逻辑
对于复杂的分组需求,可以实现自定义的分组逻辑:
Map<String, List<Person>> groupByAgeRange = persons.stream()
.collect(Collectors.groupingBy(person -> {
int age = person.getAge();
if (age < 18) return "Under 18";
else if (age < 65) return "Adult";
else return "Senior";
}));多级分组
Collectors.groupingBy支持多级分组:
Map<String, Map<String, List<Employee>>> multiLevelGrouping = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.groupingBy(Employee::getPosition)));并行流分组
对于大数据集,可以使用并行流提高分组性能:
Map<String, List<Item>> parallelGrouping = largeItemList.parallelStream()
.collect(Collectors.groupingBy(Item::getCategory));分组后的操作
分组后通常需要对各组数据进行进一步处理:

Map<String, Double> averageByGroup = students.stream()
.collect(Collectors.groupingBy(Student::getClass,
Collectors.averagingDouble(Student::getScore)));注意事项
- 分组键的选择要考虑其唯一性和稳定性
- 大数据集分组时注意内存消耗
- 并发环境下考虑使用线程安全的收集器
- 自定义分组函数应确保其行为一致