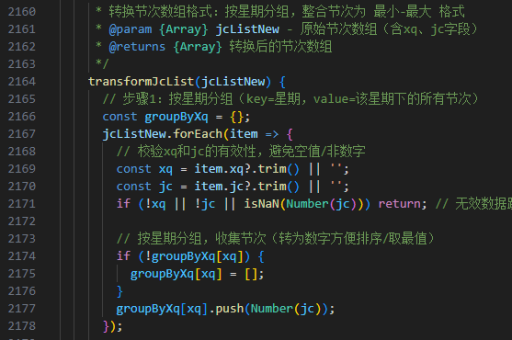
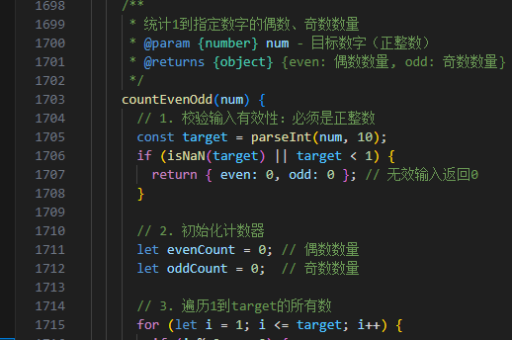
java如何识别繁体
Java识别繁体的方法
在Java中识别繁体字可以通过多种方式实现,包括使用Unicode范围判断、第三方库或API进行转换和验证。
Unicode范围判断
繁体中文的Unicode范围主要集中在\u4E00-\u9FFF之间,但简体中文也在此范围内。若要更精确地区分繁体,可以结合特定繁体字符的Unicode区块或使用正则表达式匹配常见繁体字。
boolean isTraditionalChinese(char c) {
// 示例:检查是否在繁体常见范围内(实际需更精确的Unicode定义)
return (c >= '\u4E00' && c <= '\u9FFF');
}使用OpenCC库
OpenCC(Open Chinese Convert)是一个开源简繁转换库,支持Java绑定。通过它可以将简体转为繁体,或判断文本是否为繁体。
-
添加依赖(Maven):
<dependency> <groupId>com.github.houbb</groupId> <artifactId>opencc4j</artifactId> <version>1.0.2</version> </dependency> -
使用示例:
String text = "繁體字"; boolean isTraditional = OpenCC.toSimple(text).equals(text);
调用语言处理API
如谷歌翻译API或阿里云的自然语言处理服务,可检测文本语言及字体类型(简/繁)。需注册获取API密钥。
// 伪代码示例(需替换为实际API调用)
String response = callGoogleTranslateAPI("detect", text);
boolean isTraditional = response.contains("zh-TW");ICU4J库
ICU4J是IBM提供的国际化工具库,支持简繁转换和字符属性检查。
-
添加依赖:
<dependency> <groupId>com.ibm.icu</groupId> <artifactId>icu4j</artifactId> <version>72.1</version> </dependency> -
使用示例:
import com.ibm.icu.text.Transliterator; String result = Transliterator.getInstance("Simplified-Traditional").transliterate(text);
正则表达式匹配
通过预设繁体字列表或常见繁体字符的正则表达式进行匹配。

Pattern pattern = Pattern.compile("[為為麵體]"); // 示例繁体字
boolean containsTraditional = pattern.matcher(text).find();注意事项
- Unicode判断可能不够精确,因简繁共享编码范围。
- 第三方库需注意版本兼容性和性能开销。
- API方式依赖网络,适合在线应用。