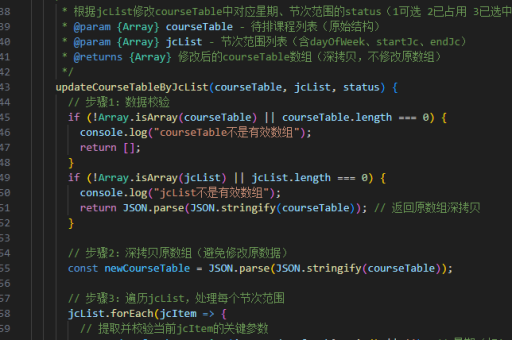
如何更快的查询java
优化Java代码查询速度的方法
使用高效的查询方法可以显著提升Java程序的性能。以下是一些关键策略:
使用索引数据结构
HashMap或HashSet提供O(1)时间复杂度的查询效率,适合快速查找场景。TreeMap虽然查询时间复杂度为O(log n),但能保持元素有序。
Map<String, Integer> map = new HashMap<>();
map.put("key", 1);
Integer value = map.get("key");数据库查询优化
对于数据库操作,采用预编译语句和索引能大幅提高查询速度:
使用PreparedStatement减少SQL解析开销
String sql = "SELECT * FROM users WHERE id = ?";
PreparedStatement stmt = connection.prepareStatement(sql);
stmt.setInt(1, userId);
ResultSet rs = stmt.executeQuery();确保查询字段已建立索引
CREATE INDEX idx_user_id ON users(id);缓存常用查询结果
实现缓存机制避免重复查询:
使用内存缓存如Caffeine
Cache<Key, Value> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();并行查询处理
利用多线程加速批量查询:

使用CompletableFuture实现异步查询
List<CompletableFuture<Result>> futures = ids.stream()
.map(id -> CompletableFuture.supplyAsync(() -> queryById(id)))
.collect(Collectors.toList());
List<Result> results = futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());查询算法选择
根据数据特性选择合适的搜索算法:
二分查找适用于有序集合
int[] arr = {1, 3, 5, 7, 9};
int index = Arrays.binarySearch(arr, 5);布隆过滤器快速判断元素是否存在
BloomFilter<String> filter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()), 1000);
filter.put("value");
boolean mightContain = filter.mightContain("value");JVM层优化
调整JVM参数提升查询性能:

增加堆内存大小
java -Xms2g -Xmx4g -jar application.jar选择合适的垃圾收集器
java -XX:+UseG1GC -jar application.jar监控与调优
持续监控查询性能:
使用JMH进行基准测试
@Benchmark
@BenchmarkMode(Mode.AverageTime)
public void testQuery(Blackhole bh) {
bh.consume(queryOperation());
}通过JVisualVM分析查询热点
jvisualvm