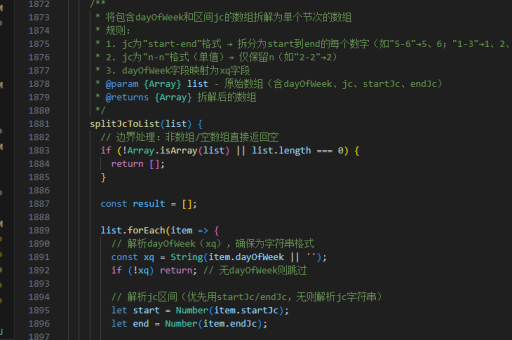
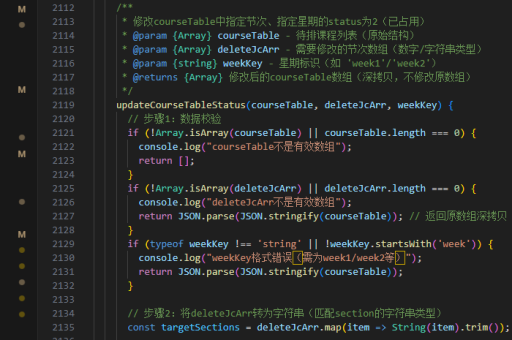
如何实现语音react
语音识别与React集成
使用Web Speech API或第三方库如react-speech-recognition实现语音输入功能。Web Speech API提供浏览器原生支持,但兼容性有限;第三方库通常封装更完善。
import { useSpeechRecognition } from 'react-speech-recognition';
const VoiceComponent = () => {
const { transcript, startListening, stopListening } = useSpeechRecognition();
return (
<div>
<button onClick={startListening}>开始录音</button>
<button onClick={stopListening}>停止录音</button>
<p>{transcript}</p>
</div>
);
};语音合成实现
通过speechSynthesis接口实现文本转语音(TTS)。需注意浏览器兼容性和用户权限问题。

const speak = (text) => {
const utterance = new SpeechSynthesisUtterance(text);
window.speechSynthesis.speak(utterance);
};
// 调用示例
speak('欢迎使用语音功能');实时语音处理优化
对于连续语音输入场景,建议使用continuous模式和interimResults参数获取中间识别结果。需处理网络延迟和设备性能差异。
const { listening, interimTranscript } = useSpeechRecognition({
continuous: true,
interimResults: true
});跨浏览器兼容方案
推荐组合使用annyang(轻量级库)和Web Speech API polyfill。对于不支持原生API的浏览器,可回退到云端语音服务如Azure Speech或Google Cloud Speech-to-Text。

if (!window.SpeechRecognition) {
import('azure-speech-browser-sdk').then(module => {
// 初始化云端识别器
});
}性能与用户体验
添加视觉反馈组件如麦克风动画、实时音量指示器。实现自动标点插入和命令词过滤功能,提升识别准确率。建议设置5-8秒的无语音自动超时机制。
<MicVisualizer
isListening={listening}
volume={currentVolume}
/>隐私与权限处理
遵循GDPR和浏览器权限模型,在首次语音交互时触发权限请求。明确告知用户语音数据的处理方式和存储策略。
navigator.permissions.query({ name: 'microphone' }).then(permission => {
permission.onchange = () => updateUI(permission.state);
});