java大数据如何处理
Java大数据处理的核心技术
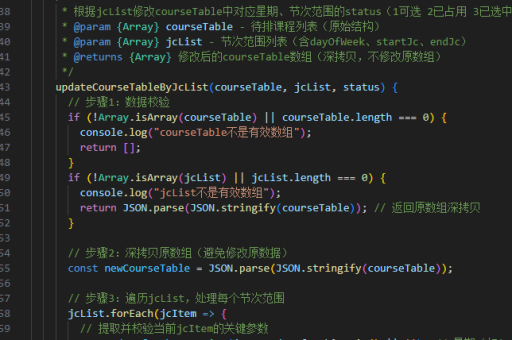
Java在大数据生态系统中占据重要地位,许多主流工具如Hadoop、Spark、Flink等都支持Java API。以下是处理大数据的关键方法和技术:
Hadoop生态系统集成
Hadoop的MapReduce原生支持Java开发,可通过org.apache.hadoop.mapreduce包实现分布式计算。典型代码结构包括继承Mapper和Reducer类,重写map()和reduce()方法。HDFS的Java客户端API(FileSystem类)支持大文件读写操作。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}Spark的Java API应用
Spark的JavaRDD接口提供弹性分布式数据集操作。通过SparkContext创建RDD后,可使用map()、filter()等转换操作和reduce()、collect()等动作操作。DataFrame API通过SparkSession提供SQL-like操作。

SparkSession spark = SparkSession.builder().appName("JavaSparkExample").getOrCreate();
JavaRDD<String> lines = spark.read().textFile("hdfs://path/to/file").javaRDD();
JavaRDD<Integer> lineLengths = lines.map(String::length);
int totalLength = lineLengths.reduce(Integer::sum);流处理框架选择
Apache Flink的DataStream API支持Java实现实时处理。通过StreamExecutionEnvironment创建流处理环境,使用flatMap()、keyBy()等操作符。Kafka消费者可通过FlinkKafkaConsumer集成。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
stream.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}).keyBy(0).sum(1).print();内存管理与优化
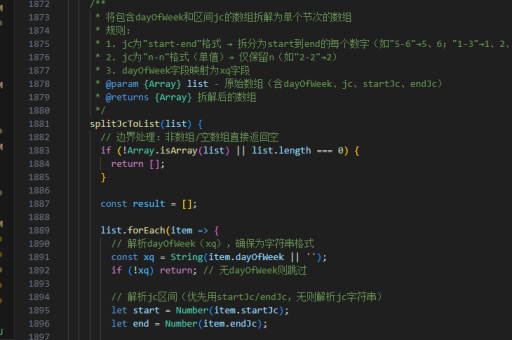
使用堆外内存技术(如ByteBuffer.allocateDirect)减少GC压力。对于海量数据,采用分块处理策略,结合缓存机制(如Ehcache或Guava Cache)。JVM参数调优包括设置合适的堆大小(-Xmx)、选择GC算法(如G1GC)。

并行处理技术
Java并发包(java.util.concurrent)提供线程池(ThreadPoolExecutor)、Fork/Join框架等并行工具。对于CPU密集型任务,可设置并行度等于处理器核心数;IO密集型任务可增加线程数。
ForkJoinPool pool = new ForkJoinPool(4);
long result = pool.invoke(new SumTask(array, 0, array.length));数据序列化方案
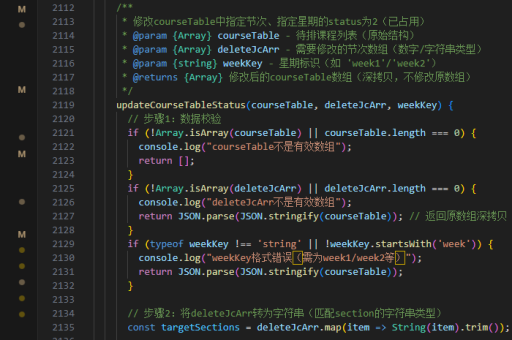
选择高效的序列化框架如Avro、Protocol Buffers或Kryo。Hadoop使用Writable接口,Spark支持Java Serializable(但性能较差),推荐注册Kryo序列化。
SparkConf conf = new SparkConf().setAppName("KryoExample");
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.registerKryoClasses(new Class<?>[]{MyClass.class});批处理与微批处理
对于定时任务,可使用Spring Batch框架实现分片处理(chunk processing)。微批处理可通过Spark Streaming的DStream或Flink的窗口函数(window functions)实现。
stream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1)
.print();性能监控与调优
利用JMX监控JVM状态,结合Spark UI或Flink Web UI分析任务执行情况。关键指标包括GC时间、任务倾斜度、Shuffle数据量。使用JProfiler或VisualVM进行内存分析。