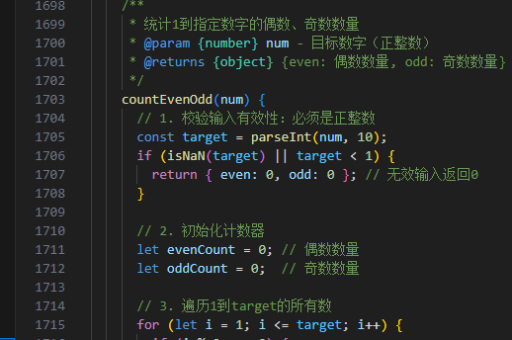
java如何去掉html标签
去除HTML标签的方法
使用正则表达式 通过正则表达式匹配HTML标签并替换为空字符串。这种方法简单但可能无法处理复杂的HTML结构或嵌套标签。
String html = "<p>Hello, <b>world</b>!</p>";
String plainText = html.replaceAll("<[^>]*>", "");
System.out.println(plainText); // 输出: Hello, world!使用Jsoup库 Jsoup是一个专门用于处理HTML的Java库,提供更精准的HTML解析和文本提取功能。
import org.jsoup.Jsoup;
String html = "<div>Sample <a href='#'>link</a></div>";
String plainText = Jsoup.parse(html).text();
System.out.println(plainText); // 输出: Sample link使用Apache Commons Text
Apache Commons Text库的StringEscapeUtils类可以处理简单的HTML转义字符,但需注意其已弃用部分方法。
import org.apache.commons.text.StringEscapeUtils;
String html = "<div>Unescape example</div>";
String plainText = StringEscapeUtils.unescapeHtml4(html);
System.out.println(plainText); // 输出: <div>Unescape example</div>注意事项

- 正则表达式可能无法处理自闭合标签(如
<img/>)或包含>的属性值。 - Jsoup会保留换行和空格,可能需额外调用
trim()处理空白字符。 - 复杂场景(如保留特定标签)需结合DOM遍历或自定义过滤规则。