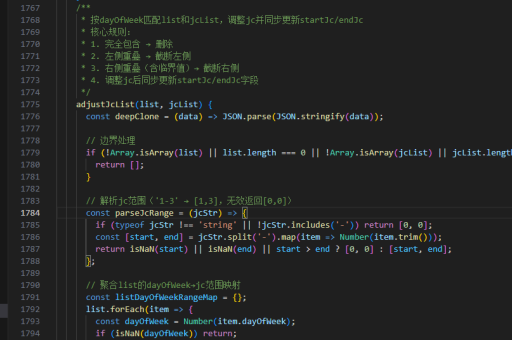
js解释器实现
JavaScript 解释器实现原理
JavaScript 解释器的核心是将源代码转换为可执行的机器指令。现代 JavaScript 引擎(如 V8、SpiderMonkey)通常采用解释器与编译器结合的混合模式,以下是关键实现要点:
词法分析与语法分析
词法分析器(Lexer)将源代码分解为 Token 序列,识别标识符、关键字、运算符等。语法分析器(Parser)根据语法规则构建抽象语法树(AST)。例如:

// 源代码
const x = 1 + 2;
// 生成的AST片段
{
type: "VariableDeclaration",
declarations: [{
type: "VariableDeclarator",
id: { type: "Identifier", name: "x" },
init: {
type: "BinaryExpression",
operator: "+",
left: { type: "Literal", value: 1 },
right: { type: "Literal", value: 2 }
}
}]
}字节码生成与解释执行
解释器将 AST 转换为字节码(Bytecode),这是一种平台无关的中间表示。V8 引擎的 Ignition 解释器采用此方式:

- 字节码比机器码更紧凑,减少内存占用
- 包含操作码(Opcode)和操作数(Operands)
- 通过虚拟机(VM)循环逐条解释执行
即时编译(JIT)优化
现代引擎通过监控热点代码触发即时编译:
- 基线编译器:生成快速但未优化的机器码
- 优化编译器:基于运行反馈进行激进优化(如内联缓存、类型特化)
- 去优化(Deoptimization):当假设不成立时回退到解释器
关键数据结构
- 作用域(Scope):管理变量访问的链式结构
- 执行上下文(Execution Context):包含变量环境、词法环境、this 绑定
- 隐藏类(Hidden Class):加速对象属性访问
简单解释器示例
以下是一个极简的 JavaScript 表达式解释器核心逻辑:
function evaluate(node, env) {
switch(node.type) {
case 'Literal':
return node.value;
case 'Identifier':
return env[node.name];
case 'BinaryExpression':
const left = evaluate(node.left, env);
const right = evaluate(node.right, env);
switch(node.operator) {
case '+': return left + right;
case '-': return left - right;
// 其他运算符...
}
// 其他节点类型...
}
}性能优化技术
- 内联缓存(Inline Cache):缓存方法调用和属性查找结果
- 逃逸分析(Escape Analysis):确定对象是否可栈分配
- 懒解析(Lazy Parsing):延迟解析非立即执行的函数
实现完整的 JavaScript 解释器需要处理闭包、原型链、事件循环等复杂特性,通常需数万行代码。现代引擎如 V8 采用分层架构,结合解释器与多级编译器实现高性能执行。